Python学习
每个Python项目都需要一个app.py 文件
声明变量:
age = 10
print(10)接收控制台输入:
name = input("What's ur name")
print("Hi" + name)转换:
birth_year = input("Birth year:")
age = 2025 - int(birth_year)
print(age)当然还有bool() float() ,使用type() 来查看这个变量是什么类型。
Python 可以使用三个引号来规避单引号和双引号的问题:
text = "this is a text".
print(text[0])Python中可以用索引来选择一个字符串中的第几个字母,如果输入负数那就是从后面往前数,[0:3] 就是从零开始数一直直到哪个字符,: 就是返回所有
格式化字符串(模板字符串):
text = "world!"
msg = 'hello,'f'{text}'
print(msg)text = "world!"
msg = f'hello,${text}'
print(msg)字符串方法
len() 可以输出字符串的长度。变量.upper() 可以把所有字符都转为大写,变量.lower() 可以把所有字符都转为小写。变量.find() 可以查找一个字符在这段文本中的位置。变量.replace(a,b) 可以可以把字符中的a换成b。
text = "hello,world!"
print('hello' in text)这个可以判断hello是否在text里面
数学函数
在使用数学函数之前我们需要引入数学模块:import math
round(x) 可以四舍五入。abs(x) 可以返回这个数的绝对值。math.ceil 可以向上取整
IF
Shift + Tab 可以使光标快速回到一行的开头
is_hot = True
is_cold = False
if is_hot:
print("it's hot today")
elif is_cold:
print("it's a cold day")
else:
print("it's a nice day")
print('Enjoy ur day')
Python中的布尔值开头要大写
逻辑运算符
has_high_income = True
has_good_credit = True
if has_high_income and has_good_credit:
print("Eligible for loan")还有or 和or not 与and not
While循环
i = 1
while i <= 5:
print(i)
i = i + 1
print("Done")For循环
for item in 'Python':
print(item)这个会依次输出组成Python的字母
for item in [1,2,3,4]:
print(item)for item in range(4):
print(item)这两个都会执行四次循环
列表方法
数组.append(x) 可以把一个数字加入数组的末尾。数组.append(x,y) 可以在x索引位置插入一个y。数组.remove(x) 可以去除数组中为x的。数组.clear() 可以去除数组中的所有内容,数组.pop() 可以去除数组的末尾的一个内容。数组.index(x) 可以返回x在数组中的索引数。
print(50 in numbers)这个也可以检测数字在数组中是否存在
数组.count(x) 可以数数组里面有多少个x。数组.sort() 方法可以把数组里面的数字从小到大排序,数组.reserve() 方法可以把数组里面的数字从大到小排序
numbers = [5,6,7,8]
numbers2 = numbers.copy()
numbers[0] = 4数组.copy() 可以把一个数组赋值给另一个数组,这样改第一个数组第二个数组就不会受到影响了
numbers = (5,6,7,8)这是一个元组,它和列表的区别就是它不能被更改
拆包
coordinates = (1,2,3)
x = coordinates[0]
y = coordinates[1]
z = coordinates[2]这么写太麻烦了,我们就可以用到拆包:
coordinates = (1,2,3)
x , y , z = coordinates当然列表也能用:
coordinates = [1,2,3]
x , y , z = coordinates字典
customer = {
'name':"John Smith",
"age":30,
"is_verified":True
}
print(customer['name'])print(customer.get('name'))也可以使用get来获取内容,但是如果要是不存在这个键值就会报错,这时候我们就可以给它设置一个默认值
print(customer.get('birthday','1995'))函数
def greet_user(first_name, last_name):
print(f'Hello {first_name} {last_name}!')
greet_user('Jim', 'Smith')Python中用def 来声明函数
def greet_user(first_name, last_name):
print(f'Hello {first_name} {last_name}!')
greet_user(last_name= 'Jim',first_name='Smith')还可以这样来指定参数对应哪个值
Try
try:
age = int(input('Age:'))
income = 2000
risk = income /age
print(age)
except ZeroDivisionError:
print('Age cannot be 0')
except ValueError:
print('Invaild value')通过except 来catch错误
注释
单行注释:#
多行注释:'''注释内容'''
类
class Print:
def __init__(self,name):
self.name = name
def print_name(self):
print(self.name)
print1 = Print('1')
print1.print_name()
print1.age = "20"
print(print1.age)
每个类里面都需要def __init__ 来初始化内部的变量。self 接收的是print1本身
如果这个类是空的直接在里面写pass 就行
继承
当定义两个类的时候,第二个类需要用到第一个类的里面的函数,就需要用到继承,要不然就又要写一遍
class Mammal:
def walk(self):
print("walk")
class Dog(Mammal):
def bark(self):
print("bark")
class Cat(Mammal):
def be_annoying(self):
print("annoying")
dog1 = Dog()
dog1.walk()
dog1.bark()
cat1 = Cat()
cat1.walk()
cat1.be_annoying()直接在类名后面加上括号然后里面写上要继承的类就可以了
模块
import converters
print(converters.kg_to_lbs(70))我们可以通过import + 文件名(无后缀) 来引入其他文件里面的函数或方法
from converters import kg_to_lbs
print(kg_to_lbs(70))或者也可以只引入单个
import ... as ... 可以给包起个别名,这样用的时候就不用都写全了
包
可以通过划分包来便于管理。我们可以新建一个文件夹作为包,然后在这个目录下新建一个__init__.py 来表示这个文件夹是一个包
我们可以通过import 包名,包名2 import 包名.文件名 来导入里面的函数方法
文件操作
from pathlib import Path
path = Path("app.py")
print(path.exists())首先要把路径初始化。
path.exists()这个可以检测这个路径是否存在
path.mkdir() 可以创建这个路径,path.rmdir() 可以删除这个目录。path.glob() 可以用来匹配文件或目录
PyPI
可以在终端通过pip install 包名 来安装包
机器学习
安装Anaconda ,然后pip install notebook jupyter notebook ,这个笔记本里面就已经内置了许多机器学习需要的组件。执行完后会在浏览器的8888端口开个网页,我们可以在里面新建一个笔记本。
import pandas as pd
df = pd.read_csv('D:\\Database\\vgsales.csv')
df这样可以查看数据集的内容
df.shape 来查看行列,df.shape 来查看各个数据的记录条数.df.values 可以看二维数组
对着一个单元格按b可以在下方插入一个新的,a可以在上方插入一个新的,双击d可以删除单元格
按一会Tab可以出现代码补全。Ctrl + / 可以注释一行
把光标悬停在方法名上面,按 Shift + Tab 可以查看形参
Ctrl + Enter 可以快速运行选中的单元格
我们需要把数据集分为输入集和输出集
import pandas as pd
music_data = pd.read_csv('D:/Database/music.csv')
X = music_data.drop(columns=['genre'])先把genre 列删除。惯例用X表示输入,Y表示输出
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
music_data = pd.read_csv('D:/Database/music.csv')
x = music_data.drop(columns=['genre'])
y = music_data['genre']
model = DecisionTreeClassifier()
model.fit(x, y)
predictions = model.predict(pd.DataFrame([[21, 1], [22, 0]], columns=x.columns))
print(predictions)我们还可以使用一个包来将数据集的一部分用来检测预测的结果是否准确
print(predictions)import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
music_data = pd.read_csv('D:/Database/music.csv')
x = music_data.drop(columns=['genre'])
y = music_data['genre']
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.2)
model = DecisionTreeClassifier()
model.fit(x_train, y_train)
predictions = model.predict(pd.DataFrame(x_test, columns=x.columns))
score = accuracy_score(y_test,predictions)
score
print(predictions)
print(score)但是这样每次预测结果都需要再训练一遍,实在是太麻烦了
import joblib 这个包可以保存和加载模型
导出:
joblib.dump(model,'music-recommender.joblib')导入:
model = joblib.load('music-recommender.joblib')决策树
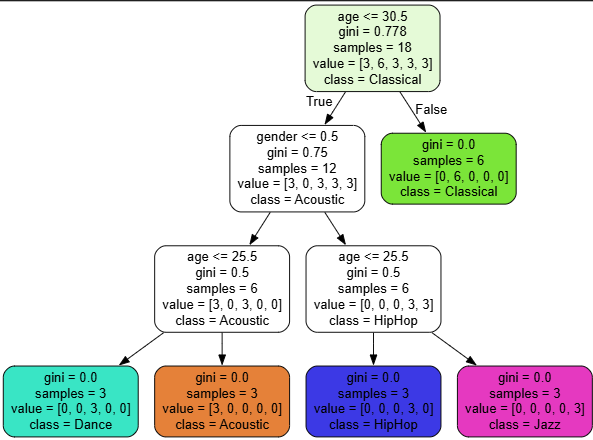
我们可以通过决策树来查看我们的模型是如何进行预测的
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
music_data = pd.read_csv('D:/Database/music.csv')
x = music_data.drop(columns=['genre'])
y = music_data['genre']
model = DecisionTreeClassifier()
model.fit(x,y)
tree.export_graphviz(model, out_file='music-reconmmender.dot',
feature_names=['age','gender'],
class_names=sorted(y.unique()),
label='all',
rounded=True,
filled=True)这样会导出一个.dot文件,我们可以在vscode安装dot插件来查看它