C 语言学习
相关资料来源:
网道
本学习笔记基于鹏哥 C 语言的视频以及互联网其它相关教程进行记录,部分章节可能会按照视频的分集名称进行命名。
C 语言最初的的标准是 ANSI (美国国家标准总局)指定的,包括 C89,C90,C99,C11 等标准,它的一些主流编译器包括但不限于 GCC Clang WIN-TC MSVC Turbo C 等。
初识 C 语言
第一个 C 语言程序
.c 后缀结尾的为源文件,.h 结尾的为头文件。在调用一些外部函数的时候,需要满足先声明再使用的要求,必须引入包含该函数接口声明的一个头文件,它规定了函数的返回类型等信息,但不包含函数的实现逻辑。编译器在编译的时候,会把你使用的外部函数在内存用一些空位填补,告诉你这里有一个“还不知道具体实现逻辑,但就是有一个函数“的地方,之后会通过链接器扫描全局把空位填补上,指向函数的实现位置。如果没有头文件规定返回的类型,在内存开辟空位的时候编译器就不知道要开辟多大,可能会造成内存浪费等等问题。
作者本人使用的是 VSCode 来写代码,但是它没有像 VS 那样的虚拟文件夹,我们需要创建 src include build 来分别存储源文件,头文件和编译后的文件
#include <stdio.h>
int main(){
printf("Hello,World!\n");
return 0;}
在输出你好世界之前,我们需要引入 stdio.h 头文件,它的全名是Standard IO ,标准输入输出。\n 是一个转义符,可以把光标挪到下一行,保持终端输出整洁,但是这个符号的作用不只有换行,还有起到给“缓冲区发信号”的一个作用。在早期计算机,屏幕读写是非常耗费性能的一个操作,如果每输出一个字母都去刷新一下那太笨了,所以就设计了缓冲区,当所有字母都加载到缓冲区后,再一股脑全部输出就会好很多,这里的换行符就起到了清空缓冲区的作用(通常)。其实缓冲区自己到一定数量就会自动清空,这个阈值可以通过宏BUFSIZ 来查看
#include <stdio.h>
int main()
{
printf("%d", BUFSIZ);
return 0;}
这里和其他高级编程语言不一样,我们需要在全面加上"%d" 来告诉后面传的是一个整数而不是一个指针。比如你可能传入了一个数字"65",对应二进制 01000001如果它以单个字符 (%c) 去读它的话,会读出来这个二进制所代表的字符 A 打印出来,而不是我们期待的整数。像这样的占位符还有很多:
常见格式占位符对比
这个表格中的 %i 很有意思,%d 和 %i 虽然在使用它打印的时候基本上没有区别,都会输出十进制数字,但是在用scanf()接受的时候就有明显区别了。 %i 允许接受八进制和十六进制数据,举个例子,如果用户输入了 012,如果你使用%d那么只会收到 12,但是用%i他就会解析你的八进制转换成 10
printf()
printf() 是一个库函数,是 C 语言给我们提供的一个函数。它的第一个形参是格式控制字符串,上面那些格式占位符只能写在这里面。写的这些占位符将会由后面的参数一一对应填补。如果你写了 n 个占位符,你给予printf()的参数应该是n+1个,如果你的参数少于了占位符,空余的那些占位符会由内存中的任意值替代。
printf("%d\n%s\n",65,"hello");
位数限制
如果你在占位符的字母前方添加数字,可以规定这个占位符的最小宽度。比如%5d就可以把这个字符限制在固定的五位,如果你给予的字符不足三位,剩下的会由空格填充,并且有效字符是右对齐的。如果你希望它是左对齐,你可以在数字前面添加一个符号来做到这一点,例如%-5d。
#include <stdio.h>
int main()
{
printf("%12f\n",123.45);
return 0;
}
小数的话就会对整数部分和小数部分同时限制。由于小数部分默认会显示六位,所以123.45实际占用的位数是十位(小数点也算一位),因为我们代码里面规定了它的最小位数必须是12,这里的打印结果就会依据它的对齐方式输出为 123.450000 。另提一嘴,如果你先用float声明了一个包含该数据的变量,再把这个变量作为参数传给函数,输出结果会变成 123.449997,这里是因为float产生了精度损失。但是如果你直接写了一个小数字面量,它默认是double类型的,所以用示例代码中的直接传参精度损失的问题就不会直观体现了。
正负号
在默认情况下printf()是不对正数显示正号的,但是对负数显示符号,如果你在字母前面加上正号那么正数也会显示正号。
#include <stdio.h>
int main()
{
printf("%+d\n",8848);
return 0;
}
// 输出结果+8848
限定小数位数
在字母前加上一个小数点和一个数字就可以限制小数部分的位数,比如%.2f就可以限制小数位数为2位,它也可以和限定宽度占位符同时使用,%6.2f 就可以在限制小数位数为2的同时限制整体位数为6。当然最小宽度和小数位数也可以用 * 变成一个通过参数传入的值:
#include <stdio.h>
int main()
{
printf("%*.*f",12,1,123.45);
return 0;
}
这里就输出了 123.5。星号由后面最先传入的几个参数依次传入。
输出部分字符串
%.[m]s可以取字符串的前 m 位。
printf("%.5s","hello,world"); //输出hello,
这一套限制宽度和精度的语法可以总结为%[宽度].[精度][类型]
由于历史遗留习惯,如果 main 函数正常运行了,我们一般会返回 0,如果异常则返回非 0。
main() 是程序的主函数,一切都从它开始执行,它是一个约定好的名字,并且有且只有一个。它不像 JS 一样不用写主函数,因为 C 语言 是一个编译型语言,如果没有main函数,编译器就不知道项目的代码应该从哪里开始;而 JS 是解释型语言,它的解释器本身就是一个程序了,包含了一个"main"了(解释器底层本身也是 C/C++写的),JS 文件本身就可以看作一个“巨大的入口文件”了。
对于缓冲区,我们还可以用手动调用的方式去清空:
fflush(stdout); // stdout 代表标准输出,即屏幕
第一个 f 代表 file,flush 则代表“冲”。我们把 stdout 传入了进去,因为在 C 语言 中,屏幕也算是一个文件
数据类型
基础
C 语言包括了以下这些数据类型:
char // 字符数据类型
short //短整形
int //整形
long //长整形
long long //更长的整形
float //单精度浮点数
double //双精度浮点数
Tip: 浮点数叫"浮点"是有说法的,比如 66.6 这个数,它可以变成 6.66 * 10 ,它的小数点发生了 "浮动"
#include <stdio.h>
int main(){
printf("%zu\n", sizeof(char));
printf("%zu\n", sizeof(short));
printf("%zu\n", sizeof(int));
printf("%zu\n", sizeof(long));
printf("%zu\n", sizeof(long long));
printf("%zu\n", sizeof(float));
printf("%zu\n", sizeof(double));
return 0;}
通过 sizeof() 运算符(并非函数)就可以打印出类型或者数据在内存当中所占的大小(单位为字节)。sizeof() 返回的是一种叫作 size_t 的数据类型(t 是 type 的缩写),他是无符号的,也就是正的,占 8 个字节,专门给这种返回大小的用。我们需要用%zu占位符去接收它,用它是因为在不同的系统下面不同类型所占的大小可能不相同,而%d只会默认按照 4 个字节去读,如果一个数据大小 8 字节,它可能就会只读一半,继续读的话就会导致错位。而%zu (size_t unsigned)会根据系统自动匹配长度去移动指针。
有趣的是,64 位的条件下,long 类型在 Windows 系统里面是 4 个字节长,而在 Linux 系统里面占了 8 个字节。这是因为 long 表示的是 系统字长(天然字长) ,设计的时候就是要求能占满一个地址的长度,而在 32 位向 64 位转型的时候,Linux 开发秉承着"自然"的精神,把long 改成了 64 位中一个地址的长度 8 位,但是 Windows 为了兼容性就没有这么干。所以在 Linux 中 long 类型 和long long类型都是 8 个字节的长度。long long 类型在 32 位一个地址最大只能容纳 4 个字节的时候就是 8 个字节的长度了,所以它需要占两个地址的大小(尽管还是用一个地址去表示它)
#include <stdio.h>
int main(){
int age = 10;
double price = 11.4514;
printf("%d\n%f", age, price);
return 0;}
直接使用类型的名字来声明变量。
我们可以用sigened和unsigned关键字来表明当前声明的变量是否具有正负号,默认情况下不单独写出就是signed。比如`unsigned int a = 1;就声明了一个无符号的整型。
整数类型的极限值
<limits.h> 提供了不同数据类型的极限常量,我们可以在代码中使用它们:
SCHAR_MIN,SCHAR_MAX:signed char 的最小值和最大值。SHRT_MIN,SHRT_MAX:short 的最小值和最大值。INT_MIN,INT_MAX:int 的最小值和最大值。LONG_MIN,LONG_MAX:long 的最小值和最大值。LLONG_MIN,LLONG_MAX:long long 的最小值和最大值。UCHAR_MAX:unsigned char 的最大值。USHRT_MAX:unsigned short 的最大值。UINT_MAX:unsigned int 的最大值。ULONG_MAX:unsigned long 的最大值。ULLONG_MAX:unsigned long long 的最大值。
可移植类型
因为不同的数据类型在不同计算机上占用的字节宽度可能是不一样的,所以<stdint.h>提供了一些类别别名来规定。
精确宽度类型
使用精度宽度类型(exact-width integer type)来确保某个正数类型的宽度是确定不变的:
int8_t:8位有符号整数。int16_t:16位有符号整数。int32_t:32位有符号整数。int64_t:64位有符号整数。uint8_t:8位无符号整数。uint16_t:16位无符号整数。uint32_t:32位无符号整数。uint64_t:64位无符号整数。
如果 int类型在当前计算机中是 32 位的,那么 int32_t 就会直接指向 int 。
最小宽度类型
最小宽度类型(minimum width type)可以保证某个整数类型的最小长度,保证所占的字节不少于指定宽度:
int_least8_t
int_least16_t
int_least32_t
int_least64_t
uint_least8_t
uint_least16_t
uint_least32_t
uint_least64_t
最快的最小宽度类型
在不同架构的处理器当中,处理不同数据的速度也是不一样的。例如 32 位的 CPU 处理 32 位数据就比处理 16 位数据要快。
int_fast8_t
int_fast16_t
int_fast32_t
int_fast64_t
uint_fast8_t
uint_fast16_t
uint_fast32_t
uint_fast64_t
int_fast8_t 就是指在当前机器下对 8 位的int的最快运算类型。
可以保存指针的整数类型。
intptr_t:可以存储指针(内存地址)的有符号整数类型。uintptr_t:可以存储指针的无符号整数类型。
最大宽度整数类型,用于存放最大的整数。
intmax_t:可以存储任何有效的有符号整数的类型。uintmax_t:可以存放任何有效的无符号整数的类型。
对于它们要分别使用专用的占位符:%jd和%ju。使用他们可以自动匹配到当前环境下最大的数据类型,比如在大多数的 64 位环境下它对应的就是long long。
在实际操作当中,应该使用宏 INTMAX_C()(无符号则使用UINTMAX_C()) 。我们来看一段代码。
#include <stdio.h>
#include <stdint.h>
int main()
{
intmax_t num = INTMAX_C(1) << 40;
printf("%jd",num);
return 0;
}
因为数字字面量编译器默认会认为它是int类型的,但是我们只要使用这个宏就,拿有符号且在64位的现代系统举例,就可以在预处理的时候直接在后面拼接 LL 来提升为long long。
宏是一种自动化且只能的文本替换规则,他可以在代码真正开始编译前用预处理器替换代码内容的一个工具。我们之前不仅可以用无参数宏来定义常量,也可以用带参数宏来使用函数进行文本替换。
刚才INTMAX_C()的宏定义就是这样的:
#define INTMAX_C(value) value ## LL
把一个参数传进去并用 ## 字符串拼接符拼接 LL
计算机如何表示小数
转换公式
在现实生活中,相信大家都是使用十进制作为基本进制,但是在计算机的世界中,他是使用的二进制,那计算机又是怎么去表示二进制的呢?我们先来看看十进制是怎么转换为二进制的:
比如我们有一个数字 0.625 ,我们可以把它乘 2 得到 1.25,我们取它的整数位1作为第一位,再把余下的0.25乘 2 得0.5,取整数位0作为第二位,最后把0.5乘 2 得到1取整数位1作为第三位,最后得到它的二进制数 0.101
在十进制中,如果我们可以用下面这个式子表示 0.625 :
0.625 = 6 * 10^-1 + 2 * 10^-2 + 5 * 10^-3
在二进制中,0.625 的二进制是 0.101,用上述式子表示的话需要把底数换成 2:
0.101 = 1 * 2^-1 + 0 * 2^-2 + 1 * 2^-3
转换公式的原理
但是,为什么要通过这样的方式来把十进制转换为二进制呢?我们来解释一下。假设我们有一个未知的十进制数V(0.625),我们先暂时用未知数表示它在二进制下的式子:
V= 0.625 = b1 * 2^-1 + b2 * 2^-2 + b3 * 2^-3 + ......
如果我们两边乘上一个 2,式子就会变成:
2V = 1.25 = b1 + b2 * 2^-1 + b3 * 2^-2 + ......
我们把 b1 单独拎了出来。这里的 b1 一定是个整数,后面的式子因为是负的指数并且还在不断变小,所以不可能超过 1,加起来是个小数。因为左右两边式子相等,所以 b1 就和左边式子的整数位 1 相等,求得 b1 = 1。
之后我们就可以去掉整数位的 1,变成:
0.25 = b2 * 2^-1 + b3 * 2^-2 + ......
之后就可以继续乘 2,得到:
0.5 = b2 + b3 * 2^-1 + ......
这时候的 b2 就和整数位相等求得为 0,之后我们再去掉整数位与乘 2 来求得 b3 (这时候整数位是 0,所以去掉后左边的式子还是 0.5)
1 = b3 + ......
这时候便能轻松得出来 b3 的值为 1,再去整数的话就为 0 了,后面不会有更多的 b 了。最后,把求得的 b1,b2,b3 组合,就可以得出来 0.625 的二进制是 0.101 啦。我们如果只观察左边的式子的话,那就是不断乘 2 然后取它的整数最后作为二进制的组成部分。
计算机如何存储
但是计算机肯定是不会直接存 0.101 的,他会存 "1.01 * 10^-1" ,那么这个在二进制中又怎么表示呢?首先我们要表示它的正负,开头的第一位表示了一个数字的正负,0 代表正数,1 代表负数,然后我们要根据科学计数法来表述它移动的位数,因为这里是整数,我们在符号位就存入 0,毕竟你在硬盘里又不能存零点几这样的数据,float 类型给了 8 位的大小作为指数位(阶码)专门来填这个步数,但是步数不能为负(主要是为了方便快速比较大小,底层是无符号的比较器最快),所以我们要个这个 -1 的 步数加上一个偏移量 127 变成正的 -1 + 127 = 126 , 我们把十进制的 126 转换成二进制:126 = 64 + 32 + 16 + 8 + 4 + 2,也就是 01111110 ,把它存进预留的 8 位指数位中。然后我们就可以把101存进去了...但是,通过上面那种方法第一位得到的数字永远都是 1,所以为了节省储存空间我们可以直接把第一个 1 省略掉,变成01,然后因为存数据的尾数位在这里没有被填满,所以后面的部分都要用 0 去补齐,我们可以得到尾数位为:01000000000000000000000
所以我们根据 符号位,指数位,尾数位 最终可以得到 0.625 存入的二进制为 : 00111111001000000000000000000000
最后计算机在取值的时候,会把 126 再减去 127 得到要移动的位数。
但是因为 float 和 double 的位数是有限的,有些小数在进行乘 2 转换的时候可能会出现无限循环的现象,无法全部存入,这样就导致了 精度丢失 。
特殊情况
但是,还是会存在例外情况的。指数位通常只有 1-254 是正常使用的,而 0 和 255 用在了特殊情况。
绝对的 0
如果用浮点类型存了一个 0,就会发生一种现象,存储的全都是零 00000000000000000000000000000000
如果这时候的规则还是默认省略 1 的话,计算机就会以为你存的是 1*2^-127,这就不是零了
非规格化数 (Subnormal)
这种情况下就是从隐藏 1 变成隐藏 0 了
如果出现了 0.5 * 10^-126 这种数(既 1 * 10^-127),就变成了非规格化数(非正规数)。以 float 类型为例,它最小只能存 1 * 10^-126 ,而刚才的数小于了它,这时候我们就要把指数位全部标记为 0 来表示这个数是个非格式化数(这时候偏差值就是 126 而不是 127 了),尾数位的数字也要变化,我们可以根据这个公式来算出尾数位应该存什么
Value = 0.f * 2^-126
可以得出来 0.f = 0.5,既 1 2^-1,写成二进制小数就是 0.12 ,这样尾数位就要表示成10000000000000000000000 。如果是别的除不尽的数字的话,比如 0.6 10^-126, 把 0.6 的二进制求出来是0.100110011001... ,把它塞进有限的尾数位,就是0000 0000 0100 1100 1100 1100 1100 1101 。非规格化数会导致精度下降,之前有 23 位去存数字,现在为了补前面的那个零,第一个数字变成了 1,如果零越多那占的越多,可以用来表示的有效数字就越来越少,全面全是 0 了,这样就导致了精度的下降,这就是渐进式下溢出
无穷大
正常情况下,因为指数位只有八位,最多只能存到 126 步,也就是 254。如果继续存的话,数据就会溢出并丢失,为了避免这种现象,当指数位达到最大的时候,FPU 硬件电路里设计了一个饱和截断机制(Saturation),如果继续增加的话会强制锁定阶码为 11111111 ,然后把尾数位全部清空为 0。这时候,这个数据就变成了 无穷大 (正无穷还是负无穷还要看符号位)。或许我们会产生疑问,既然都溢出了,还要把它变成无穷大干什么呢,这难道不是无意义的吗?不,它恰恰就是为了表示这个数据已经到达了极限,而不是任由它继续增加变成更加无意义的数据。
NaN
当阶码全是 1,而尾数为却不全为零的时候,这个数据就是 NaN (Not a Number) 了。NaN 分为两种类型,一种是 qNaN (Quiet) ,另一种是 sNaN (Signaling)。这两个的阶码同样都是1,但是前者在尾数位的第一位放上1;后者会把第一个标记为0,但是后面必须存在至少一个1 。比如你执行了一个错误的除法逻辑float result = 0.0 / 0.0; ,这时候底层的电路会发现这个错误,但是它不能直接拒绝运算,它会直接输出一个标志错误的 NaN 二进制。NaN 的尾数位利用了最高位(第 1 位)来表示 NaN 的类型。实际上它包含了巨大的信息容量,因为剩下的 22 位都是留给硬件厂商或开发者来自定义底层错误代码(Payload)的,这使得 NaN 拥有几百万种不同的状态。
qNaN
这是一种“安静的”NaN,如果它产生了不会抛出错误,而是会继续参与到运算当中。它还具有传染性,如果利用一个数字与它进行运算操作,那么那个变量也会变为 NaN。这样去设计并不是出于什么别的目的,只是为了保证程序能够尽量正常运行,而不至于一下子就爆出个错误让程序终止运行。比如在显卡渲染画面的时候,渲染几百个像素,如果一个像素变成了 NaN 就去终结程序太不聪明了,这个像素一般就会被渲染成黑色的或者是透明的,而不至于影响大局。
sNaN
这种数据很致命,只要参与运算就会立刻终结程序。在特殊的场景里面,数据是不容得一丝错误的,为了遵循 Fail-Fast(快速失败原则),只要出现了错误就立刻终结程序,而不是让它继续运行下去酿成更大的错误。
常量
C 语言中的常量分为一下几种:
字面常量
const修饰的常变量#define定义的标识符常量枚举常量
变量
C 语言的变量分为全局变量和局部变量,如果全局变量与局部变量重名,会优先使用局部变量。在声明变量的时候最好给他初始化,否则编译器可能会报错。不初始化的情况下变量存的是一个随机数。
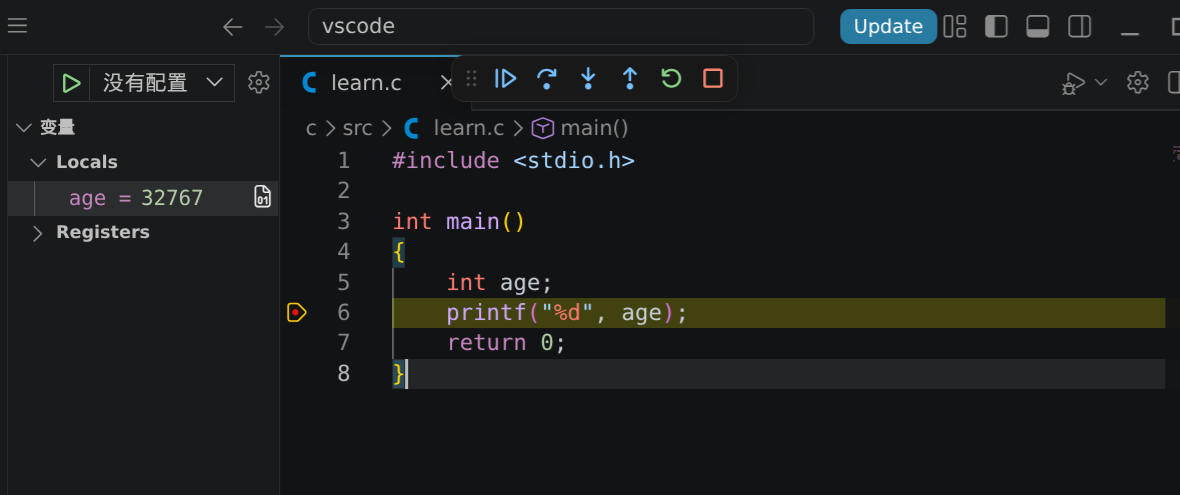
这里直接未初始化就打印了变量,可见情况与上面所说的相同。
#include <stdio.h>
int main(){
int num1 = 0;
int num2 = 0;
scanf("%d %d", &num1, &num2);
int sum = num1 + num2;
printf("%d",sum);
return 0;}
scanf() (Scan Formatted)是一个输入函数,允许你在终端输入数据并分配到两个地址中。它后面不能直接写变量名,否则它只能取来num1 和 num2 变量的值而不知道他们地址在哪里,也就不能进行修改,我们要用 & 取地址符来获取。这时候可能就会产生一个问题,为什么 printf() 就不需要取地址呢?因为这个函数只是将变量打印出来而不需要修改它,所以取来一个值就足够了。
在 Visual Studio 中使用这个函数可能会报错不安全,并要求我们使用 scanf_s() ,但是这是 VS 编辑器的一个特有函数,不具有跨平台行,我们可以直接在文件顶部加上 :
#define _CRT_SECURE_NO_WARNINGS
这个预处理指令来规避。
预处理指令是在编译前就执行的代码,到时候编译器拿到的就是预处理指令处理之后的代码,它并不知道这条指令的存在。
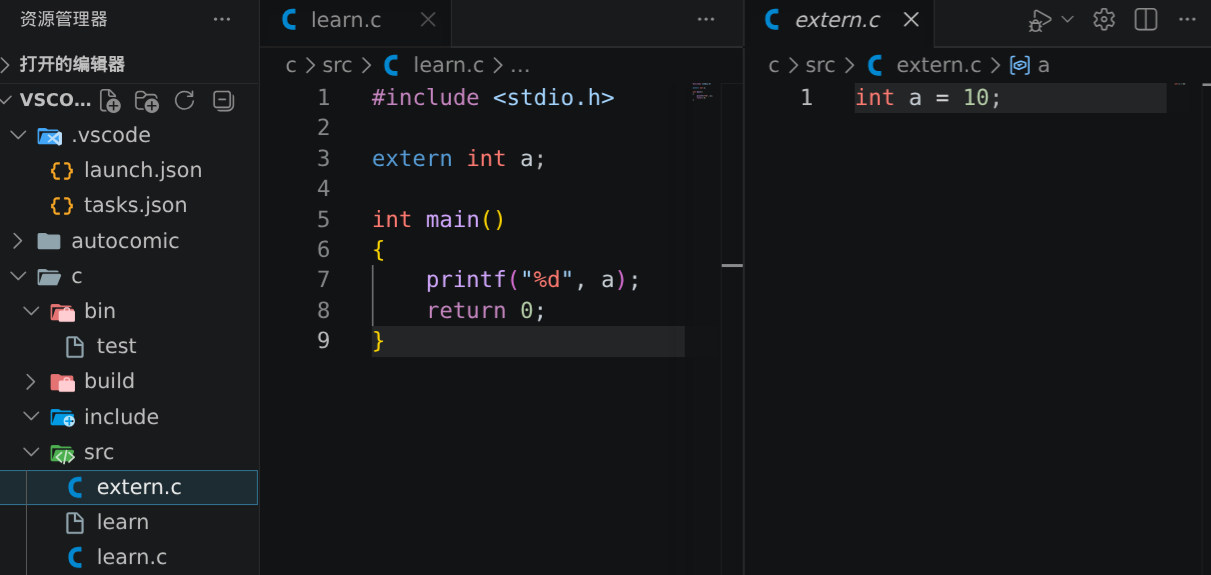
使用关键字 extern (外部的)可以使用其他文件定义的变量,后面要跟上它的类型与名字。我们不需要写上它所引用的文件的文件路径,查找的事情是连接器去干的。如果我们在 VSCode 当中发现无法正常输出这个外部引用的变量,很有可能是 tasks.json 中配置了只编译当前文件,如需解决这个问题只需要修改表示要编译的文件路径由"${file}"改为当前目录下的所有文件即可:
{
"tasks": [
{
"type": "cppbuild",
"label": "C/C++: gcc 生成活动文件",
"command": "/usr/bin/gcc",
"args": [
"-fdiagnostics-color=always",
"-g",
"${fileDirname}/*.c",
"-o",
"${fileDirname}/${fileBasenameNoExtension}"
],
"options": {
"cwd": "${fileDirname}"
},
"problemMatcher": [
"$gcc"
],
"group": {
"kind": "build",
"isDefault": true
},
"detail": "调试器生成的任务。"
}
],
"version": "2.0.0"
}
这里面的 -o 下面紧跟的路径是指定的文件输出路径,-g表示是否启用调试。编译路径不需要一个特定的字符去指定它,当排除其他所有情况后 gcc 就会默认剩下的那个是编译路径。
C 语言中的局部变量的声明周期从进入局部作用域开始,离开而结束。全部变量的声明周期就是整个程序的生命周期。
字面常量
#include <stdio.h>int main(){
30;
3.14;
'w';
"abc";
if (2 > 1)
{
printf("true");
}
return 0;}
像这种直接写出来,字面上就是一个常量的就叫字面常量。比如这个代码块里面的 30 3.14 2 > 1 中的 2 和 1,都是字面常量
const
#include <stdio.h>int main(){
const int a = 1;
printf("%d",a);
return 0;}
const 修饰的常变量是不变的。它本质上还是一个变量,但是因为有 const 关键字而变的无法被修改,所以叫常变量
#include <stdio.h>
int main(){
const int n = 1;
int arr[n] = {0};
return 0;}
就比如这段代码如果这样编写就会报错,因为声明数组的时候方括号只能传入一个常量,但是这里的 n 是一个 常变量,导致不能正常使用,进一步论证了 const 修饰的只是一个拥有只读权限的变量而不是一个纯粹的常量。
标识符常量
#include <stdio.h>
#define MAX 100
int main(){
printf("%d\n",MAX);
int a = MAX;
printf("%d\n",a);
return 0;}
使用 #define 可以定义一个全局的常量,它不具有类型,也无法被修改。
枚举常量
#include <stdio.h>
#define MAX 100
enum Color{
RED,
GREEN,
BLUE
};
int main(){
int num = 10;
enum Color c = RED;
printf("%d", c);
// > 0}
枚举定义的数据都对应着一个数字,它是一个常量,它们按照顺序依次自增。这里通过 enum 关键字声明了一个属于 Color 枚举类型的变量 c 并赋值了 RED,这里的 RED 对应的数值就是 0
字符串
我们在前面已经接触到了 char 类型用于存储字符变量,但是它只能存储一个字符,如果我们需要存储一个字符串,可以用数组来做到这一点。
#include <stdio.h>
int main(){
char arr[10] = "abcdef";
return 0;}
这里面我们就定义了一个长度为 10 的数组,足够把一个个字符“串”起来放进去变成字符串。当然,我们不必每次创建字符串都去数数有几个字来确保定义的数组长度足够长,如果我们中括号里面什么都不写,它会自动帮我们确定长度。
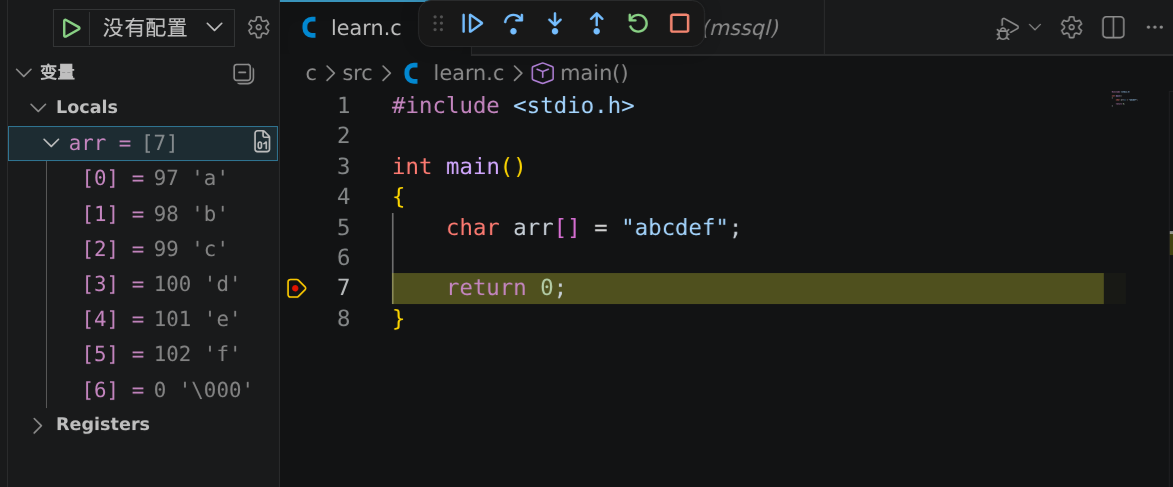
如果我们打断点观察一下这个数组,我们会发现它的末尾藏了一个 \0 ,它是一个结束字符,当计算机在内存中读到它的时候就会知道这个字符串已经读取完毕,从而停止,就像 mRNA 上面的终止密码子一样,如果缺少了它计算机就会一直往下读取。
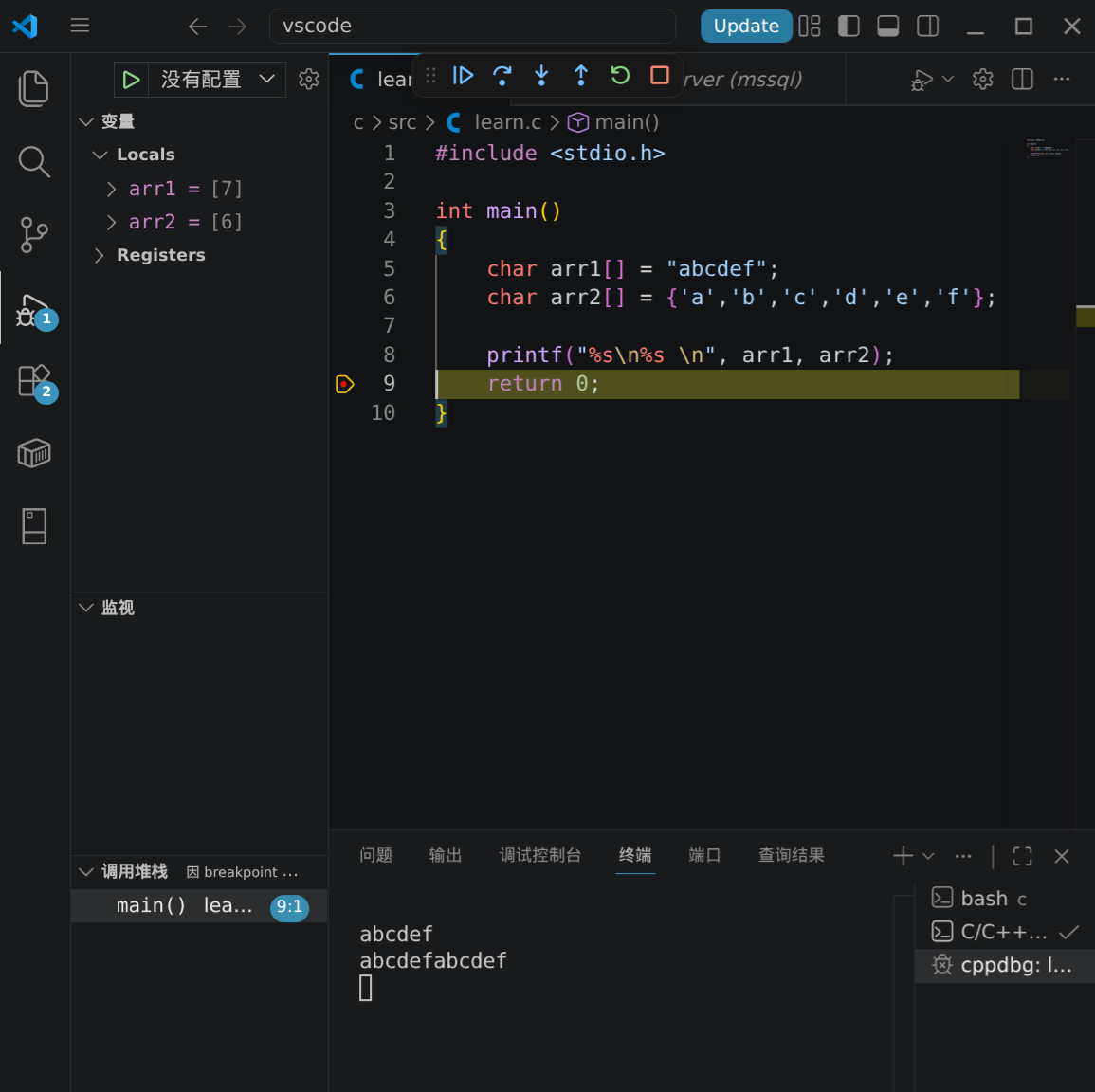
如果我们采用一个一个字符放进去不写\0,就会发现终端打印出来的内容和预期不同。这是因为在打印第二个数组的时候缺少了 \0 ,继续在内存中读取到了 arr1 的内容并打印了出来
#include <stdio.h>#include <string.h>
int main(){
int len = strlen("abc"); // 3
printf("%d",len);
return 0;
}
转义字符
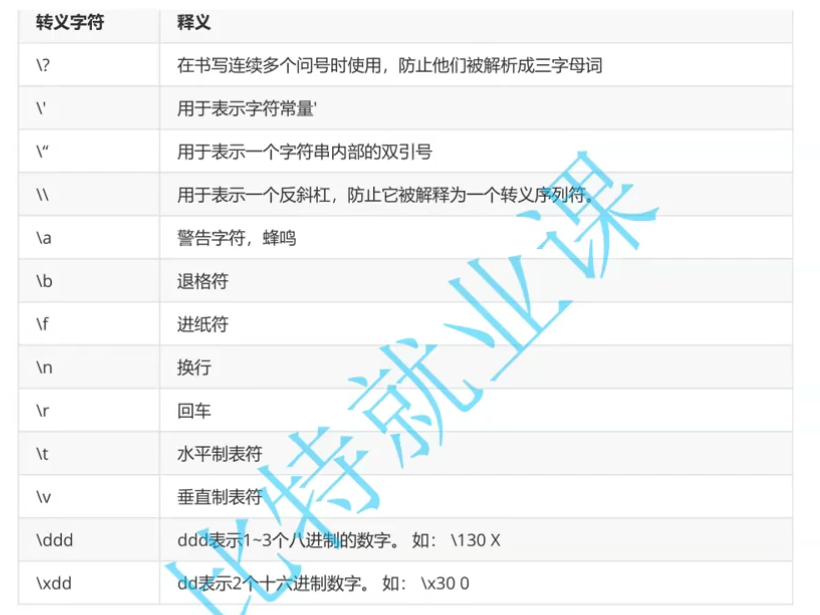
\t 的效果就和按下 Tab 键一样
#include <stdio.h>
int main() {
printf("%c",'\130');
}
\ddd 可以用三个数表示八进制。在示例代码中会输出 X。因为 130 在十进制用是 88 ,在 ASCII 中也就是 X 这个字母。但是如果在后面输入比 7 大的单个数字就不会起作用了,它就不算作这个转义字符作用范围内了,因为八进制的单个位数只有 0~7.\xdd,可以用两个数表示十六进制的数字,比如\x63表示 99 对应 c。这两个所表示的整体都只算作一个字符占位。
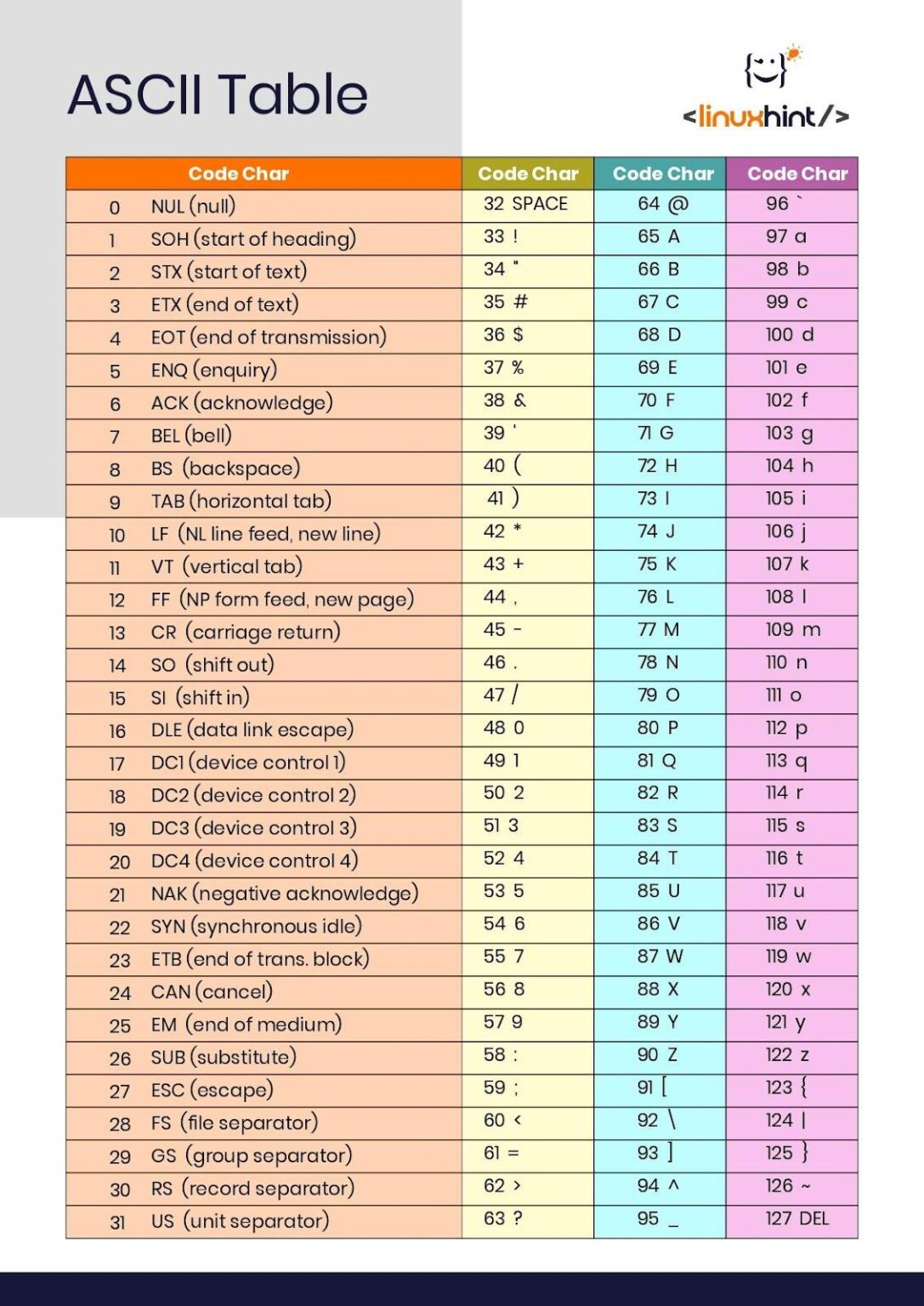
这个就是 ASCII 码表。可以从中看到,小写字母的码数比大写字母的多 32
选择语句
#include <stdio.h>
int main()
{
int input = 0;
printf("加入比特\n");
printf("要好好学习吗?");
scanf("%d", &input);
if (input == 1)
{
printf("好 offer\n");
}
else
{
printf("烤地瓜");
}
}
循环语句
#include <stdio.h>
int main()
{
int line = 0;
printf("加入比特\n");
printf("写代码\n");
while (line < 20000)
{
printf("写代码:%d\n", line);
line++;
}
if (line >= 20000)
{
printf("好offer\n");
}
else
{
printf("继续努力\n");
}
return 0;
}
goto 语句
你可以用goto跳转到有指定标签名的代码,但是因为其会破坏结构化变成而不建议使用。注意,goto只能在同一个函数里面跳转,无法跳转到其他函数。
#include <stdio.h>
int main()
{
beatles:
printf("let it be");
char test = 'a';
if (test == 'a')
{
goto beatles;
}
return 0;
}
这里的示例代码就是在if的代码块跳转到了外部的beatles标签并从这里再继续往下执行代码。
函数
#include <stdio.h>
int add(int n, int m)
{
int sum = 0;
sum = n + m;
return sum;
}
int main()
{
int a = 1;
int b = 2;
int result = add(a, b);
printf("%d",result);
return 0;
}
C 语言函数的形参要先定义好类型。函数前面的int代表的是返回类型,它告诉了我们这个函数会返回什么类型的数据,如果没有返回值,可以用void表示。
int add(int n, int m)
{
return (n + m);
}
刚才的示例代码中的return后面也可以直接接上一个表达式来简化代码。
数组
#include <stdio.h>
int main()
{
int arr[10] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
printf("%d\n", arr[8]);
int i = 0;
while (i < 10)
{
printf("%d", arr[i]);
i = i + 1;
}
return 0;
}
数组是包含了一组相同类型的数据的集合,声明它的关键字代表了里面数据的类型。它后面的方括号在声明时代表了这个数组的长度,使用时代表了选取数据的下标。我们之前学习的字符串就是一个用char声明的数组,包含了多个字符,连起来就成了字符串。如果我们想打印出里面的所有数据,就可以采用循环遍历的方式。
位运算符
取反运算符
~ 可以对二进制中的0和1翻转。
#include <stdio.h>
int main()
{
short a = 0b0000000000000000;
printf("%b",(unsigned short)~a);
return 0;
}
这里的输出结果就是1111111111111111。使用位运算符C语言会自动把这个数据提升到 int 类型进行计算,所以我们这里使用了(unsigned short) 来对取反后的结果进行了一次显示转换。%b 是一个二进制类型的占位符,但是它只在 C23 及以后标准存在,较老的编译器可能无法识别。
与运算符
#include <stdio.h>
int main()
{
printf("%.8b",(unsigned char)(0b10010011 & 0b00111101));
return 0;
}
与运算符可以按位数逐个比较两个二进制并返回一个值,相同则是1,不同则是0,示例代码则会返回00010001。
与运算符也可以与赋值运算符一起使用:
#include <stdio.h>
int main()
{
char a = 0b10010011;
char b = 0b00111101;
a &= b;
printf("%.8b",a);
return 0;
}
此时输出还和上面的一样保持不变。这里简化了代码,直接用运算符一步比较然后赋值。
或运算符
或运算符(|)也是将两个二进制进行比较并获取到一个值。如果比较的两个比特位其中有且仅有一个为1就返回1,否则返回0。它也能和赋值运算符一起使用:|=
左移运算符
左移运算符<< 可以把二进制数整体向左移动两位,后边空出来的位置会用零填充。比如10001010 << 2的结果就是1000101000。它也可以和赋值运算符结合变成<<=。这个运算符就相当于把一个数乘以2的指定次方数,比如刚才操作就是给那个数字乘以了2的二次方。
右移运算符
同理,右移运算符(>>)是把数字整体向右移动,但是尾部移过去超出的值会被舍弃,头部空出来的会用0填充。比如10001010>>2就会变成00100010。对数据进行这个操作相当于给它除以2的指定次方,上述例子就是除以了2的二次方。
指针
概念
指针是一个变量,是一个值,这个值代表了一个内存地址,就相当于指向某个内存地址的路标。int* intPtr 星号前面代表指向值的类型,后面则是指针的类型,中间的星号其实可以放在类型和名称之间的任何位置。比如char* charPtr就是一个指向char类型数据的指针。
#include <stdio.h>
int main()
{
int num = 8848;
int* intPtr = #
printf("%p",intPtr);
return 0;
}
int * fii, * bar;
我们也可以像这样一行声明两个指针变量。
int** foo;
如果想让一个指针指向另一个指针,可以使用两个星号。int则表示第二个指针指向的是一个int类型的整数。
* 运算符
* 可以取出一个指针所指向数据的值
void increment(int* p) {
*p = *p + 1;
}
这里面*p就表示指针所指向的那个值,对他修改就会改变指针所指向的那个地址里面的值。当星号在等号左侧使用的时候表示的原始地址本身,这里面就是表示直接对原始地址的值进行操作,在等号右侧就是直接把那个值复制过来然后进行操作。
如果我们需要把一个特别大的值放入函数进行加工,直接作为参数传入可能会非常消耗性能,但是如果只传入一个指针,就可以直接对原始地址的数据进行操作减少开销。
#include <stdio.h>
int main()
{
int num = 1;
int *ptr1 = #
int **ptr2 = &ptr1;
printf("%d", **ptr2);
return 0;
}
该示例代码让一个指针指向了另一个指针,另一个指针指向了一个数字,我们应该怎么取出来num里面存的值呢?我们首先要拿到ptr2的值,它存的是ptr1的地址,我们使用一个*可以取出来ptr1存的值,也就是num的内存地址,然后我们再次使用*就可以取出来num存的值了。
& 运算符
& 可以获得一个变量的内存地址。
#include <stdio.h>
void increment(int *p)
{
*p = *p + 1;
}
int main()
{
int x = 1;
increment(&x);
printf("%d", x);
return 0;
}
我们把x的地址传入了一个函数,这个函数的形参也是一个指针用于接受地址,然后对它指代的值进行增量操作。
初始化指针
如果你不对指针进行初始化,编译器会给它随机分配一个地址,如果此时往它的地址写入内容,可能会写入到一个非常重要的地方而导致系统崩溃,从而造成非常严重的后果,这也就是我们常说的野指针,十分危险。
指针的运算
指针与整数值的加减运算
#include <stdio.h>
int main()
{
short *j;
j = (short *)0x1234;
j = j + 1; // 0x1236
return 0;
}
指针并不遵循整数运算的法则,它的加减表示的是指针的移动。这里我们给j赋予了一个地址,但是你会发现这里我们对他进行了一次显式转换,这是因为0x1234这个字面量本身是int类型的,我们需要先给他转换成指针的类型才能够正常的加减。如果我们给他加1,因为short类型占两个字节,指针的位置就会移动一个short类型所占用的长度,换成其它类型也同理。所以在移动一个单位后,里面存的地址就会变成0x1236。
指针与指针的减法
因为指针和指针的加法是非法的,没有任何实际意义,故不做赘述。
指针的减法可以理解为计算两个指针在内存中相距的距离,它会返回一个ptrdiff_t类型的值,用占位符%td接受,想使用它要先引入<stddef.h>头文件。如果用高位内存减去地位内存返回的就是正值,反之则负。
#include <stdio.h>
#include <stddef.h>
int main()
{
short *j1;
short *j2;
j1 = (short *)0x1234;
j2 = (short *)0x1238;
ptrdiff_t dist = j2 - j1;
printf("%td",dist);
return 0;
}
这里的输出结果是2,因为他们两个之间差了2个short类型所占的字节宽度。
指针与指针的比较运算
比较运算是比较各自的内存地址哪个更大,返回1或0
函数
函数指针
因为函数本身就是内存里面的一段代码,所以我们也可以用指针来获取函数。我们需要通过这样的格式声明一个指针函数:返回值类型 (*指针名称)(返回值类型) = &函数名,比如下面这段示例:
int print(int a) {
printf("%d\n",a);
return a;
}
int (*print_ptr)(int) = &print;
我们必须在指针名称外面加上一个括号,这是由 C语言 的运算顺序所决定的。如果我们去掉它,就会变成int *print_ptr(int) = &print; 这样编译器就会以为我们声明了一个返回 int * 的整型指针。
不要觉得这样的语法很反人类,因为编译器需要这些信息才能正常编译,知道函数返回值类型,参数类型。
我们还可以通过函数指针来直接调用函数:
(*print_ptr)(10);
//等同于
print(10);
函数名在 C语言 当中本身就是一个指向代码函数的指针,通过函数名就能获取函数地址,也就是说print和&print本质上是一个东西。
所以,对于任意函数,都有五种调用函数的写法。
// 写法一
print(10)
// 写法二
(*print)(10)
// 写法三
(&print)(10)
// 写法四
(*print_ptr)(10)
// 写法五
print_ptr(10)
这种特性的一个应用是,如果一个函数的参数或返回值,也是一个函数,那么函数原型可以写成下面这样。
int compute(int (*myfunc)(int), int, int);
上面示例可以清晰地表明,函数compute()的第一个参数也是一个函数。
但是向我们这样声明函数指针实在是太反人类了,我们不妨使用typedef来给它整个别名。它的语法是: typedef [原类型] [新名字],比如:
typedef (*PointFunction)(int);
int print(int a){
printf("%d\n",a);
}
PointFunction print_ptr = print;
int result = print_ptr(10);
函数原型
在 C 语言中,编译器是从上到下阅读代码的,因此,你在 main() 使用一个函数的时候,它必须在主函数前面就已经声明了,否则会报错。但是我们可以先在主函数之前给出一个函数原型,之后在补上函数的实现逻辑。
int twice(int);
int main() {
twice(num);
}
int twice(int num) {
return 2 * num;
}
我们也可以在给予原型的时候在括号里面把参数名写上,虽然这样对编译器并没有什么用,但是增强了代码的可读性。
int twice(int num);
exit()
使用 exit() 可以直接退出整个函数,stdlib.h 里面定义了它。它可以传入两个参数,EXIT_SUCCESS (相当于1)和 EXIT_FAILURE (相当于0)来分别表示程序是成功运行了还是异常退出了。我们还可以使用 stdlib.h 里面定义的 atexit() 函数来注册在程序结束前执行额外的函数,我们需要给他传入一个函数指针,在退出程序任务下达后它注册的这个函数就会执行。
#include <stdio.h>
#include <stdlib.h>
void notice(void) {
printf("The program stopped runnning!");
}
int main()
{
atexit(notice);
exit(EXIT_FAILURE);
return 0;
}
函数说明符
static
每次调用函数的时候,其内部的变量都会重新初始化,但是只要我们给函数内部声明的变量加上 static 关键字,它就不会每次都初始化,数据会保留下来。
#include <stdio.h>
#include <stdlib.h>
int increment()
{
static int num = 0;
num++;
return num;
}
int main()
{
increment();
increment();
increment();
increment();
int result = increment();
printf("%d\n", result); //输出5
return 0;
}
你在代码里面声明一个静态变量的时候,不能用另外一个变量来初始化它,只能用一个常量。在底层当中,static 声明的变量并非存储在栈中,而是存放在 静态/全局数据区 ,不会随着函数的销毁而销毁了。编译的时候这个是要硬编码在可执行文件当中的,如果你给他赋值一个需要在运行时才能知道确切值的变量的话,编译器会报错。
我们还可以给函数最前面加上 static 变量来声明,这样该函数就只能在当前文件内访问,而外部文件无法访问。
在这个静态/全局数据区里面,分为两个区域:.data 区和 .bss 区。
.data区存放非零初值的全局变量和static声明的变量,而.bss存放的是没有被赋值为 0 的全局变量和static声明的变量。假如你声明了一个全是 0,巨大的地图数组,如果直接全部编译到软件里面,对硬盘的占用将会非常恐怖,但是如果存储到.bss区,它会留下一句指令,等到程序运行的时候再在内存中开辟这么多 0 的一个空间。
普通变量声明的时候,赋值就直接写在编译后的机器码里面了。但是如果赋值的数据非常巨大,C 语言会把这个数据作为一个常量放到 .rodata 区里面存储。
当函数想要操作一个 static 声明的内部变量的时候,它会区静态区获取这个变量然后作修改,再把这个值写回到静态区,这样当这个函数运行完毕销毁之后存入静态区的变量还在那里,当函数的下一个函数周期开始的时候获取它就是上次函数处理完毕之后的结果了。
既然这个静态区是直接编译到程序里面的,那么对静态数据进行操作后,这个数据会不会就这样永远在静态区被改变了呢?答案是不会,当程序运行的时候,会把静态区里面的数据原封不动复制到内存一份,对数据进行操作也是对内存里面的数据进行操作,不会影响到静态区的 "原件"。